XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 21 setembro 2024

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.
.png)
How to train YOLOv8 on a custom Dataset — Picsellia
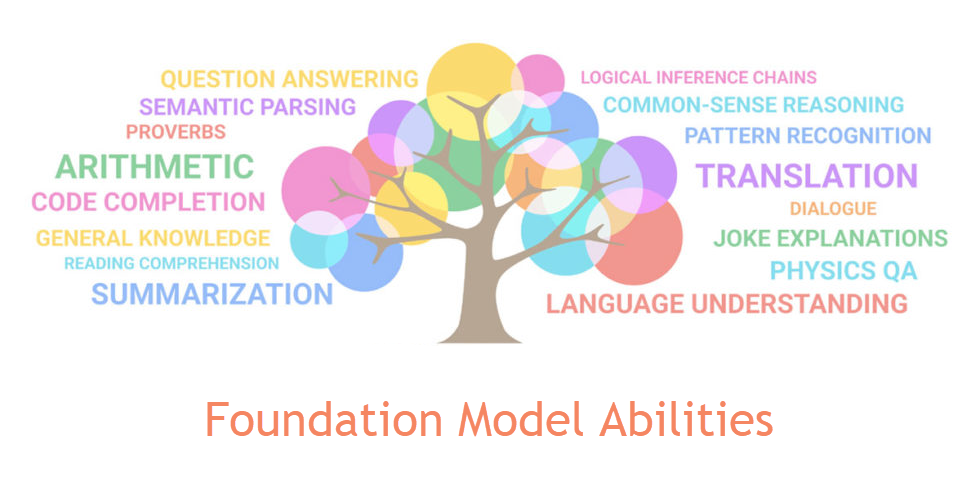
GPT-3 and the rise of foundation models

ACL Search Tool

PDF] i-Code: An Integrative and Composable Multimodal Learning

PGPS9K Dataset Papers With Code

PDF] mMARCO: A Multilingual Version of the MS MARCO Passage
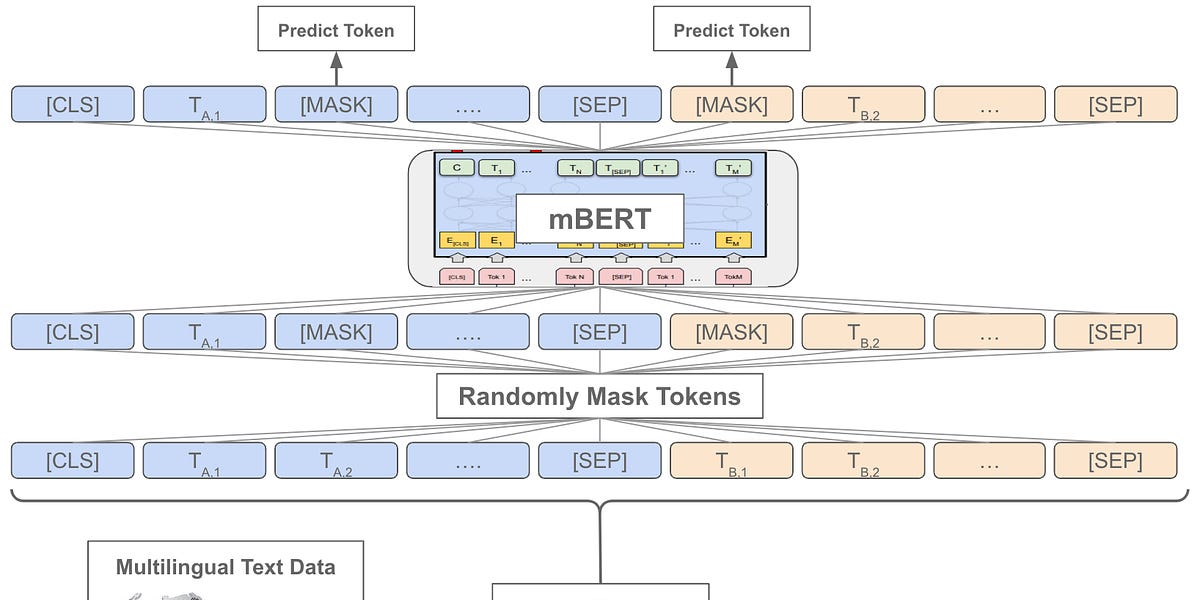
Many Languages, One Deep Learning Model
7 Top Open Source Datasets to Train Natural Language Processing
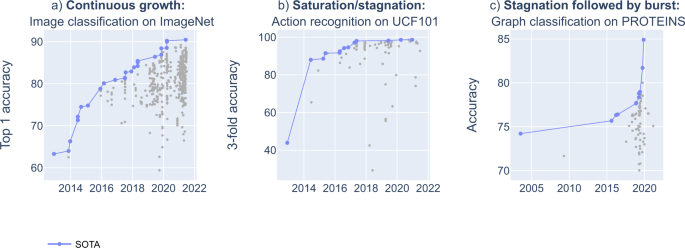
Mapping global dynamics of benchmark creation and saturation in

The OIG Dataset
XQuAD Dataset Papers With Code

XQuAD (de) Benchmark (Question Generation)
Recomendado para você
-
 ME6016 ADVANCED I.C ENGINES - SHORT QUESTIONS AND ANSWERS21 setembro 2024
ME6016 ADVANCED I.C ENGINES - SHORT QUESTIONS AND ANSWERS21 setembro 2024 -
300+ TOP I.C. ENGINES Objective Questions and Answers PDF MCQs, PDF, Internal Combustion Engine21 setembro 2024
-
Marine Engineering Interview Questions and Answers, PDF, Diesel Engine21 setembro 2024
-
Recent Cisco 500-210 Exam Questions PDF Version [2023]21 setembro 2024
-
 Engine Trouble Questions & Answers21 setembro 2024
Engine Trouble Questions & Answers21 setembro 2024 -
 Graduate marine engineering(GME)important questions21 setembro 2024
Graduate marine engineering(GME)important questions21 setembro 2024 -
 Automobile Engineering MCQ (Multiple Choice Questions) - Sanfoundry21 setembro 2024
Automobile Engineering MCQ (Multiple Choice Questions) - Sanfoundry21 setembro 2024 -
 Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu21 setembro 2024
Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu21 setembro 2024 -
Solved could you answer this questions by typing please.21 setembro 2024
-
 Top 30 Mobile Testing Interview Questions & Answers for 202321 setembro 2024
Top 30 Mobile Testing Interview Questions & Answers for 202321 setembro 2024

![Recent Cisco 500-210 Exam Questions PDF Version [2023]](https://media.licdn.com/dms/image/D4D12AQEaxtsp3YJv4w/article-cover_image-shrink_600_2000/0/1689924865615?e=2147483647&v=beta&t=dxk4XIIW9PyH9yb3IwwyFPB-Fe9ypzogihO3DFKrlQw)

você pode gostar
-
 Dragon Ball Z: Kakarot terá Vegeta, Gohan e Piccolo como21 setembro 2024
Dragon Ball Z: Kakarot terá Vegeta, Gohan e Piccolo como21 setembro 2024 -
Which rooms entity is better?21 setembro 2024
-
Kelly Godoy - CEO KG ASSESSORIA - ASSESSORIA KG21 setembro 2024
-
 Game Jolt - Share your creations21 setembro 2024
Game Jolt - Share your creations21 setembro 2024 -
 Glossário Fashion: TODOS OS TIPOS DE XADREZ!21 setembro 2024
Glossário Fashion: TODOS OS TIPOS DE XADREZ!21 setembro 2024 -
 Alternate World Pharmacy Anime Debuts in July 2022! - QooApp News21 setembro 2024
Alternate World Pharmacy Anime Debuts in July 2022! - QooApp News21 setembro 2024 -
 Boost Your Chess Rating: Master Openings, Tactics, and Endgames for 500+ Elo — Eightify21 setembro 2024
Boost Your Chess Rating: Master Openings, Tactics, and Endgames for 500+ Elo — Eightify21 setembro 2024 -
 Ultimate Trainer for Resident Evil 2 Remake (DX11 Non-RT) file - ModDB21 setembro 2024
Ultimate Trainer for Resident Evil 2 Remake (DX11 Non-RT) file - ModDB21 setembro 2024 -
 Assassin's Creed 2 - Game Movie21 setembro 2024
Assassin's Creed 2 - Game Movie21 setembro 2024 -
 Attack on Titan Season 4 Part 3: Release Date, Trailers, Episodes, and News - IMDb21 setembro 2024
Attack on Titan Season 4 Part 3: Release Date, Trailers, Episodes, and News - IMDb21 setembro 2024

